Featured
Table of Contents

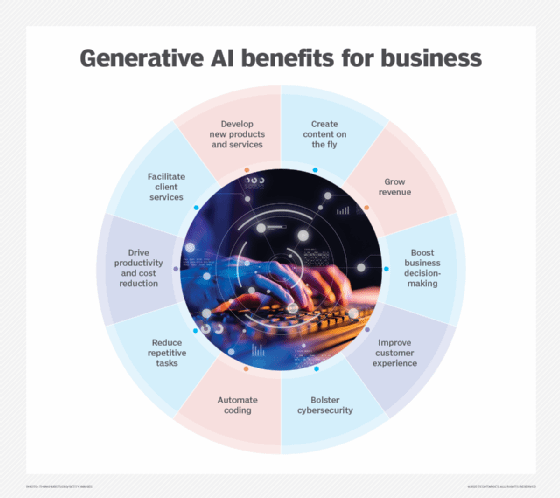
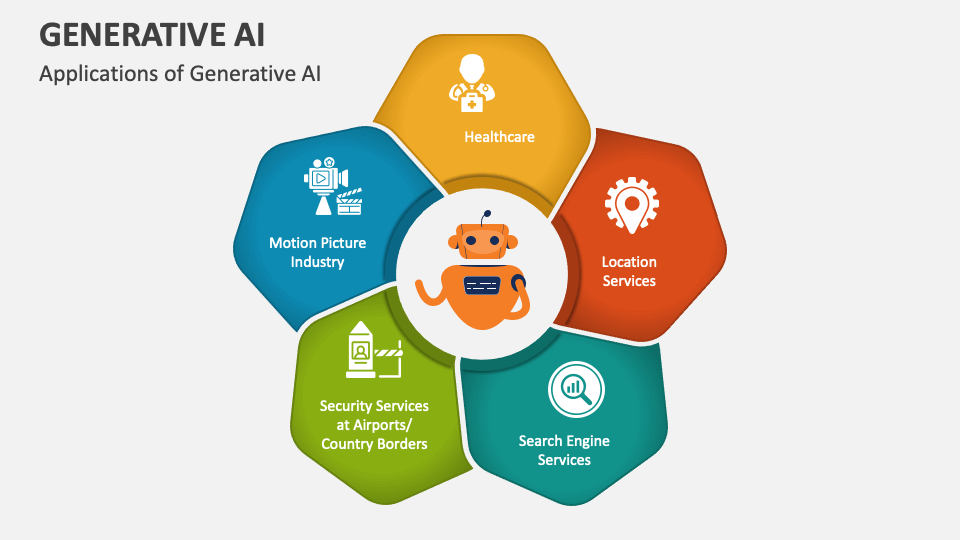
Generative AI has service applications past those covered by discriminative models. Let's see what general versions there are to use for a wide variety of problems that obtain remarkable outcomes. Various algorithms and associated designs have been created and educated to develop brand-new, sensible material from existing data. Some of the models, each with distinctive devices and capabilities, are at the center of innovations in fields such as photo generation, message translation, and information synthesis.
A generative adversarial network or GAN is an artificial intelligence framework that puts both neural networks generator and discriminator against each various other, therefore the "adversarial" part. The competition between them is a zero-sum video game, where one representative's gain is another representative's loss. GANs were designed by Jan Goodfellow and his coworkers at the College of Montreal in 2014.
Both a generator and a discriminator are frequently executed as CNNs (Convolutional Neural Networks), specifically when functioning with pictures. The adversarial nature of GANs exists in a game theoretic scenario in which the generator network should complete versus the adversary.
Sentiment Analysis
Its opponent, the discriminator network, tries to compare examples drawn from the training information and those attracted from the generator. In this scenario, there's always a winner and a loser. Whichever network falls short is updated while its opponent continues to be unchanged. GANs will certainly be considered effective when a generator creates a phony sample that is so persuading that it can deceive a discriminator and human beings.
Repeat. It finds out to find patterns in sequential data like written message or spoken language. Based on the context, the model can predict the following component of the series, for example, the following word in a sentence.
What Is Machine Learning?
A vector represents the semantic qualities of a word, with comparable words having vectors that are close in value. 6.5,6,18] Of training course, these vectors are simply illustratory; the actual ones have many even more measurements.
At this stage, details regarding the setting of each token within a sequence is added in the form of one more vector, which is summarized with an input embedding. The result is a vector mirroring words's preliminary meaning and position in the sentence. It's after that fed to the transformer neural network, which consists of 2 blocks.
Mathematically, the relations between words in an expression resemble distances and angles between vectors in a multidimensional vector room. This mechanism is able to identify refined methods even far-off information aspects in a series impact and rely on each other. In the sentences I poured water from the bottle right into the cup up until it was full and I put water from the pitcher into the mug till it was empty, a self-attention mechanism can differentiate the meaning of it: In the previous situation, the pronoun refers to the cup, in the last to the pitcher.
is utilized at the end to compute the likelihood of different outcomes and select the most probable option. The produced result is added to the input, and the whole process repeats itself. What are the applications of AI in finance?. The diffusion design is a generative model that produces brand-new data, such as images or sounds, by resembling the data on which it was educated
Think about the diffusion model as an artist-restorer who researched paintings by old masters and now can repaint their canvases in the same design. The diffusion design does approximately the same thing in three main stages.gradually introduces sound into the initial image until the outcome is just a disorderly collection of pixels.
If we go back to our example of the artist-restorer, straight diffusion is managed by time, covering the paint with a network of fractures, dirt, and oil; often, the paint is revamped, adding particular information and removing others. resembles examining a painting to understand the old master's initial intent. What are neural networks?. The design carefully evaluates just how the included noise alters the information
What Is Sentiment Analysis In Ai?
This understanding allows the design to successfully reverse the process later. After learning, this version can reconstruct the altered data using the process called. It begins with a noise example and removes the blurs step by stepthe very same means our musician removes pollutants and later paint layering.
Unrealized depictions contain the fundamental elements of data, enabling the model to restore the initial info from this encoded significance. If you change the DNA molecule simply a little bit, you get a completely various organism.
What Are The Limitations Of Current Ai Systems?
Say, the woman in the 2nd leading right image looks a bit like Beyonc yet, at the exact same time, we can see that it's not the pop singer. As the name suggests, generative AI transforms one kind of image right into an additional. There is a range of image-to-image translation variations. This task involves drawing out the design from a well-known painting and applying it to an additional photo.
The result of using Secure Diffusion on The results of all these programs are pretty similar. Nonetheless, some individuals keep in mind that, on average, Midjourney draws a bit more expressively, and Secure Diffusion complies with the request a lot more plainly at default setups. Researchers have actually additionally made use of GANs to produce manufactured speech from message input.
What Are Examples Of Ethical Ai Practices?

The main task is to perform audio evaluation and develop "vibrant" soundtracks that can alter relying on how individuals engage with them. That said, the music might alter according to the environment of the video game scene or depending upon the strength of the individual's exercise in the fitness center. Read our write-up on to find out more.
So, rationally, video clips can also be created and converted in much the exact same way as photos. While 2023 was marked by innovations in LLMs and a boom in image generation innovations, 2024 has actually seen substantial innovations in video generation. At the start of 2024, OpenAI introduced a truly remarkable text-to-video version called Sora. Sora is a diffusion-based version that produces video from static noise.
NVIDIA's Interactive AI Rendered Virtual WorldSuch artificially produced data can help develop self-driving vehicles as they can use produced digital world training datasets for pedestrian discovery. Of training course, generative AI is no exemption.
When we state this, we do not imply that tomorrow, makers will certainly rise against humanity and ruin the world. Allow's be honest, we're respectable at it ourselves. Since generative AI can self-learn, its behavior is tough to regulate. The results offered can typically be much from what you anticipate.
That's why so several are implementing vibrant and smart conversational AI versions that consumers can connect with through text or speech. In addition to consumer service, AI chatbots can supplement advertising and marketing initiatives and support inner interactions.
Natural Language Processing

That's why so lots of are executing dynamic and intelligent conversational AI models that customers can interact with via text or speech. In enhancement to client service, AI chatbots can supplement advertising initiatives and support interior communications.
{kind=link}
Table of Contents
Latest Posts
How Does Ai Process Big Data?
Can Ai Think Like Humans?
How Does Ai Work?
More
Latest Posts
How Does Ai Process Big Data?
Can Ai Think Like Humans?
How Does Ai Work?